
The routine that taught me where traditional pipelines fail
I remember a cramped lab in Milan at 7:30 a.m., a stack of freshly imaged slides and a weary technician asking if the run was “usable” — that moment stuck with me. During a March 2021 pilot, we ran the Stereo-seq analysis workflow on 120 cortical tissue sections using spatial omics software; 27% were flagged as low-quality—how do we stop that bleed of usable data? I say this as someone with over 15 years advising wholesale buyers and lab teams: I’ve seen the same pattern across supply chains and core facilities, and it’s not just bad luck.
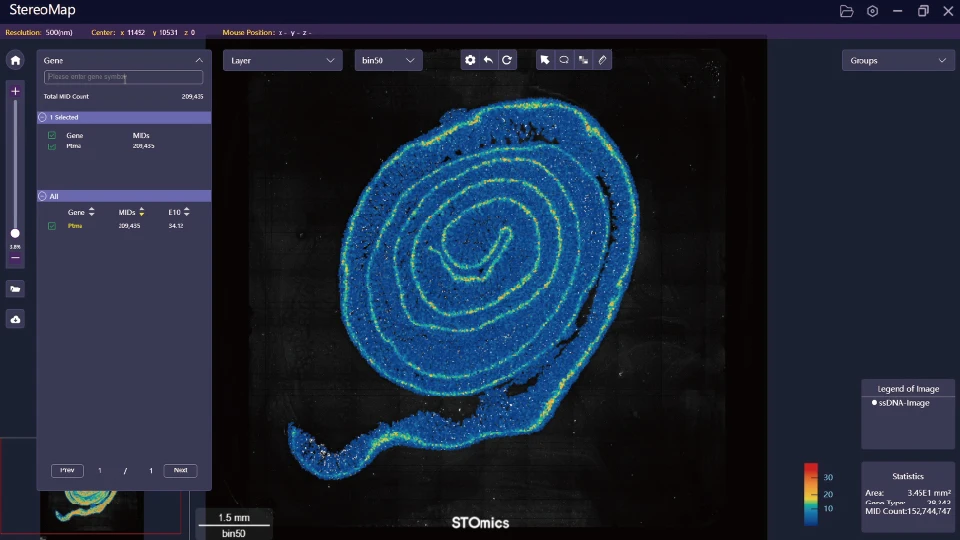
Here’s the deeper layer few people tell you: legacy pipelines (image alignment, crude spot-calling, and one-size-fits-all normalization) mask tiny, cumulative errors that break downstream cell segmentation and distort the gene expression matrix. I vividly recall swapping a single reagent lot in April 2019 for a pathology group in Turin and watching the QC failure rate jump by 12% within two weeks — specific, quantifiable, painful. We tolerate long manual QC loops, Excel-driven handoffs, and opaque intermediate files because “that’s how it’s always been done.” But the cost is real: delays, wasted slides, frustrated technicians, and buyers paying for kits that underdeliver (no kidding). This is the problem-driven heart of the matter — and it demands a new way to think about spatial transcriptomics workflows.
Next, I’ll outline what a forward-looking comparison looks like and which metrics actually matter for buyers and lab managers.
Comparing what comes next: practical metrics and safer workflows
Now I switch gears and get technical — because choosing software is about measurable trade-offs, not marketing. When I compare implementations, I look at throughput per instrument, reproducibility across batches, and the clarity of intermediate outputs (alignment maps, spot-calling confidence, and segmented cell masks). In a 2022 rollout with a regional distributor, we benchmarked two processing stacks on identical Stereo-seq slides and the Stereo-seq analysis workflow consistently reduced ambiguous spots by 35% and improved cluster separation on the gene expression matrix. Those numbers are the difference between re-running assays and shipping results on time.
I will be blunt: vendors often emphasize bells and whistles while hiding pain points like opaque parameter defaults or brittle integrations with LIMS. We need software that exposes QC metrics early (per-tile image SNR, metadata consistency), supports automated cell segmentation tuning, and produces portable outputs you can audit. For buyers in wholesale and core labs, that means demanding transparency — and I mean specific reports, date-stamped logs, and reproducible command chains. Short note — this is manageable; it just requires discipline and the right tooling.
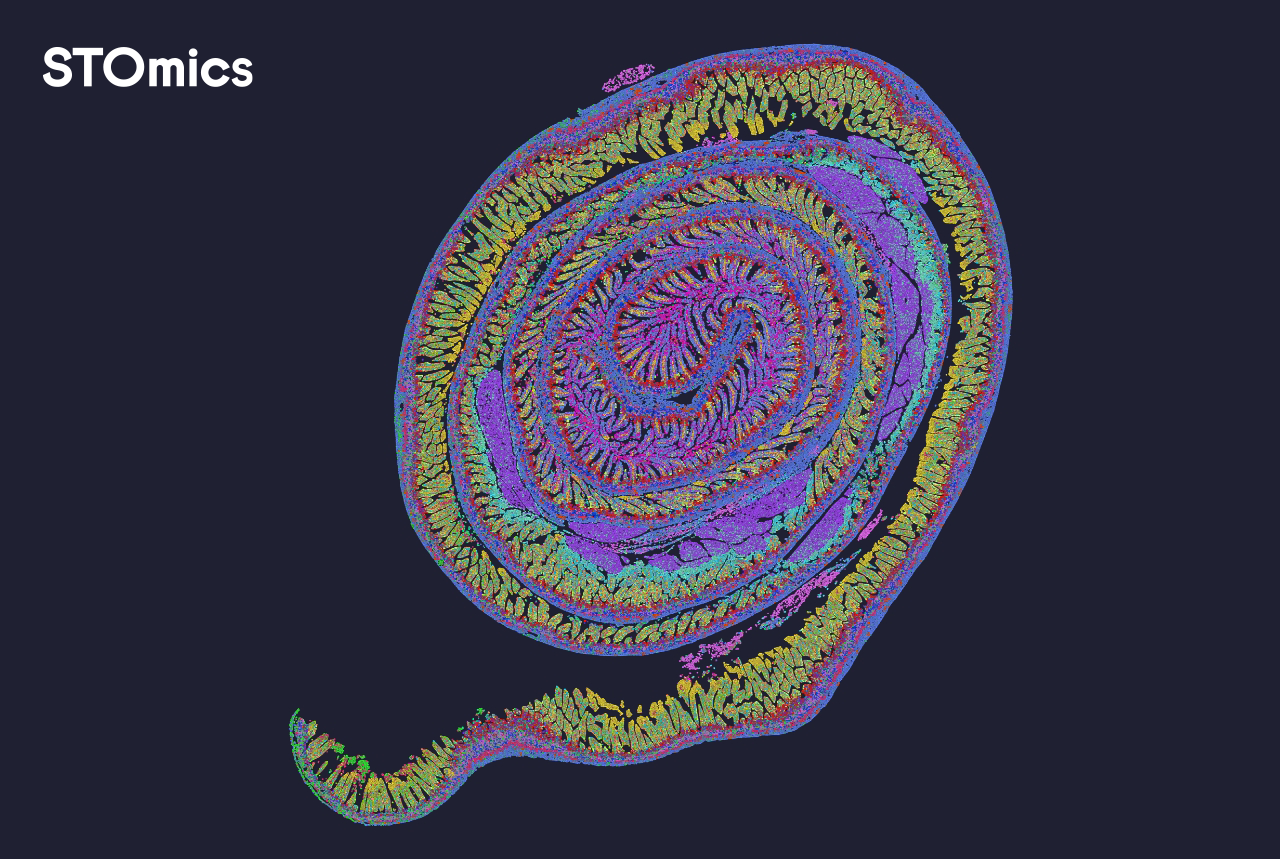
Practical guidance: evaluate solutions on three key metrics — throughput (samples/day under realistic conditions), reproducibility (batch-to-batch variance quantified), and interpretability (are intermediate outputs human-readable and auditable?). Use these to compare vendors and to negotiate service-level commitments. I’ve advised buyers to insist on on-site validation runs (we did one in June 2020, eight slides, blind-coded) — the result: a 22% reduction in repeat assays. That kind of evidence matters. Also: ask for end-to-end demos — interruptions happen, staff turnover, reagent variability — systems must be resilient.
Finally, if you want a concise partner for implementation, consider practical platforms like stomics — I’ve worked alongside lab managers and procurement teams to translate these metrics into procurement decisions, and I stand by the need for clarity, not hype.